Что такое сбор семантического ядра для сайта? — чтобы было легче ответить на этот вопрос, давайте разберем один момент с трафиком:
Самый лучший, горячий, а главное бесплатный трафик идет из поисковых систем Яндекса, Гугла и подобных. И чтобы мы могли бесплатно привлекать этот трафик на свой сайт, нам нужно подобрать правильные ключевые запросы (слова, словосочетания), по которым пользователи и будут к нам приходить.
Подбор ключевых запросов для продвижения, как раз и называется «сбор семантического ядра для сайта» — и в этой статье мы подробно разберем (с примерами) что такое семантическое ядро, как его правильно собирать и что для этого потребуется.
Содержание статьи:
- Семантическое ядро что это?
- Семантическое ядро как составить правильно за 7 шагов
- Заключение и рекомендация
Семантическое ядро что это?
Семантическое ядро — это просто набор слов и словосочетаний, по которым мы хотим получать посетителей из поисковых систем на свой сайт.
Чтобы вы понимали, — просто так, Яндекс и Гугл не будут пригонять к вам на сайт бесплатный трафик, так, как они (поисковики) по умолчанию не понимают, для кого и для каких целей сделан ваш сайт. Соответственно наша задача, дать им (поисковикам) понять по каким поисковым запросам мы хотим получать посетителей.
Для этого, с помощью специальных инструментов (о них расскажу ниже) мы подбираем подходящие поисковые запросы и создаем на нашем сайте одноименные страницы под них. Так, мы даем поисковым системам понять, какая тема у данной страницы и по каким поисковым запросам на нее должны попадать пользователи.
Резюмируя сказанное:
Семантическое ядро — это просто набор подходящих запросов пользователей по которым мы хотим получать бесплатный трафик и под которые будем создавать страницы на своем сайте.
Пример моего семантического ядра с пояснениями
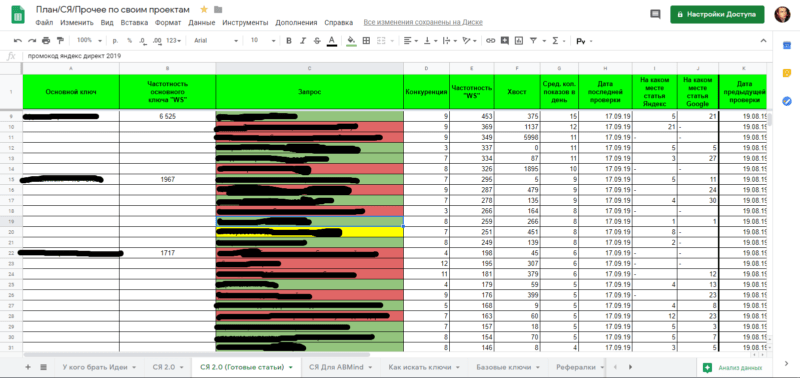
Вот так выглядит мое семантическое ядро для сайта, возможно вам покажется, что оно сложное, но это совершенно не так. Для наглядности давайте чуть его разберем. Какие важные части есть в данном семантическом ядре:
Столбец «Запрос» — в этот столбик попадают поисковые запросы пользователей, под которые я написал или только собираюсь написать статью для своего блога.
— Зеленый цвет — означает, что статья вышла в топ и ее не нужно переписывать;
— Желтый цвет — означает, что статья движется к топу;
— Красный цвет — означает, что статья не в топе, нужно подождать или переписать ее.
Столбец «Конкуренция» — в нем отображается конкуренция по выбранной поисковой фразе, т.е. сколько примерно сайтов продвигаются по этому запросу и как сложно будет по нему выйти в топ (чем больше число, тем сложнее выйти).
Столбец «Частотность» — показывает сколько раз в месяц запрашивают эту фразу в Яндексе.
Столбец «Хвост» — отображает количество хвостов к выбранной фразе.
— Хвост это дополнение к основному запросу. Например я хочу написать статью под запрос «купить ноутбук в Питере» и все слова, которые будут добавляться к этому запросу, будут для меня хвостами. Например во фразе «купить ноутбук в Питере в рассрочку» — словосочетание «в рассрочку» будет для меня хвостом, также слово «хороший» будет хвостом во фразе «купить хороший ноутбук в Питере».
Почти такая же таблица с поисковыми запросами должна получиться и у вас. И именно благодаря ей вы будете наполнять сайт подходящим контентом и получать бесплатный трафик.
Зачем нужно делать сбор семантического ядра для сайта
Что такое СЯ мы разобрали, теперь давайте разберем на кой фиг оно нужно и почему без него будет сложно.
Грубо говоря СЯ — это план по продвижению сайта. Конечно мы можем наполнять сайт и так, «на глазок», добавляя на него разные ключевые слова, которые по нашему мнению приведут нам посетителей, но сразу скажу, это заведомо провальный вариант.
Имейте в виду, хоть Яндекс и Гугл говорят о том, что качество контента важно (и это действительно так), но они не будут пригонять к вам трафик, если не смогут понять для какой поисковой фразы подходит ваш контент. Не забывайте, что поисковики — это всего лишь машины, которые работают по определенным алгоритмам и не могут оценить вашу статью/страницу с точки зрения человека.
И знаете, что самое ироничное в этом всем? У вас может быть нереально качественная и полезная статья, но она будет очень далеко от первого места в поисковой выдаче. А у какого-нибудь конкурента/коллеги, который написал откровенный бред, но оптимизировал его под поисковую фразу, будет большое количество бесплатного трафика и его статья будет занимать первые места в выдаче. Несправедливо? Да, но с этим придется считаться.
Поэтому, чтобы не делать работу в холостую, а получать стабильный, положительный результат, нам нужно заранее собрать семантическое ядро и наполнить его подходящими поисковыми запросами, под которые мы будем писать статьи или оптимизировать страницы.
Семантическое ядро как составить правильно за 7 шагов
Сразу скажу, все шаги ниже подходит для сбора семантического ядра только для информационных сайтов и блогов. Для интернет магазинов, агрегаторов и прочих сайтов, куда нет смысла писать статьи, семантическое ядро собирается чуть по другому.
Наша главная задача при подборе семантического ядра — это найти запросы пользователей, с большой частотностью, с маленькой конкуренцией и с возможностью написать под найденную фразу развернутую статью. Если вы будете придерживаться такой формулы поиска, вы быстро подберете подходящие ключевики.
Шаг 1: Подбираем идеи
На этом этапе наша задача выписать направления, для которых мы будем подбирать ключевые запросы. Под направлениями я имею в виду темы или рубрики на вашем сайте, которые будут объединять общие по смыслу статьи и ключевые фразы.
Например на моем сайте, «направления» выглядят так:

Придумать или искать идеи для рубрик можно двумя способами:
Способ 1: Берем идеи из головы.
— Если вы хорошо знаете свою сферу, для вас не составит большого труда придумать рубрики для будущих статей, поэтому вы просто садитесь и выбрасываете на листок все идеи для рубрик, которые пришли к вам в голову.
Способ 2: Берем идеи у коллег/конкурентов.
— Для этого мы открываем Яндекс и вбиваем в него какую-нибудь общую фразу, конкретизирующую нашу сферу, плюс добавляем слово «Блог». Затем начинаем смотреть, какие рубрики есть у наших коллег и выписываем понравившиеся на листок.
На этом этапе нам нужно выписать хотя бы 10 рубрик (можно и больше).
Например у меня для этого блога получились собрать следующие направления (рубрики):
• Создание сайта
• Удаленный заработок
• Интернет профессии
• Яндекс Директ
• Интернет маркетинг
• Привлечение клиентов
• Поисковое продвижение
• Продвижение в соц. сетях
• … и подобные направления
У вас должен получиться примерно такой же список, со своими рубриками.
Шаг 2: Расширяем направления, собираем «грязные» ключи
Следующий шаг, это собрать «грязные» ключевики для рубрик. Для этого мы открываем Яндекс Вордстат и вводим туда название первого направления, которое мы придумали.
Для наглядности я буду подбирать запросы из своего списка (из примера выше). Первым в списке у меня идет направление «Создание сайта», которое я и вбиваю в Вордстат.
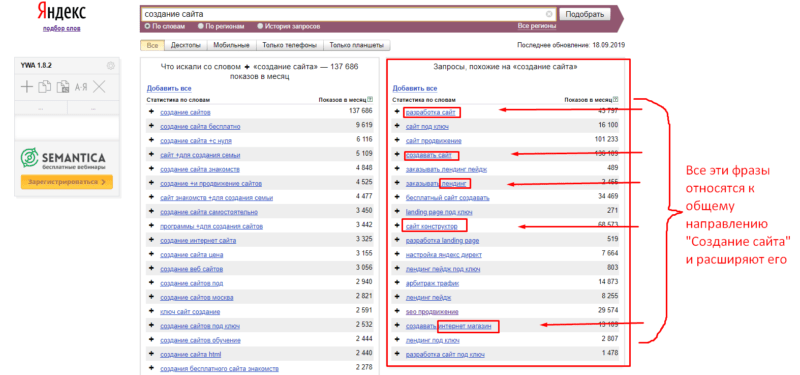
На данном этапе меня интересует не левая колонка Вордстата, а правая, в которой Яндекс показывает похожие запросы. Благодаря этой колонке я смогу подобрать фразы, которые имеют прямое отношение к моему направлению и расширяют его.
В данном случае мне подходят фразы:
— Разработка сайт
— Создавать сайт
— лендинг
— landing
— сайт конструктор
— Интернет магазин
Все эти фразы имеют одну общую черту — они все так или иначе связанны с созданием сайта. Поэтому я беру эти фразы и добавляю к себе в таблицу. Получается следующая картина:

Затем я точно также беру следующую фразу (в моем случае это фраза — «разработка сайт»), вбиваем ее в вордстат и опять ищу новые «грязные» ключи.
Затем я опять копирую из правой колонки новые ключи и добавляю их в свою таблицу. Точно также я делаю со всеми остальными запросами. А когда все «похожие запросы» закончатся, мы берем следующее направление и точно также по нему проходимся собирая все «грязные» ключевики из правой колонки Вордстата.
ВНИМАНИЕ!
Яндекс не разделяет некоторые части речи, поэтому фразы «создание сайта» и «создать сайт» — это для него две совершенно разные фразы, с разной поисковой выдачей и частотностью.
В результате у вас должна получиться таблица с минимум десятью рубриками, и в каждой рубрике должно быть минимум по пять «грязных» ключей. После этого наступает простой, рутинный шаг — автоматический сбор ключевиков.
Шаг 3: Делаем сбор семантического ядра для сайта, через программу
На этом этапе нам нужно собрать все хвосты к «грязным ключевикам». Вручную мы это делать не будем (мы ведь не психи), вместо этого мы воспользуемся бесплатной программой для парсинга ключевых слов под названием Slovoeb (и это не шуточное название). Скачать программу можно на официальном сайте.
После того, как мы скачали программу, нам нужно подключить к ней почту Яндекса. Делается это следующим образом:
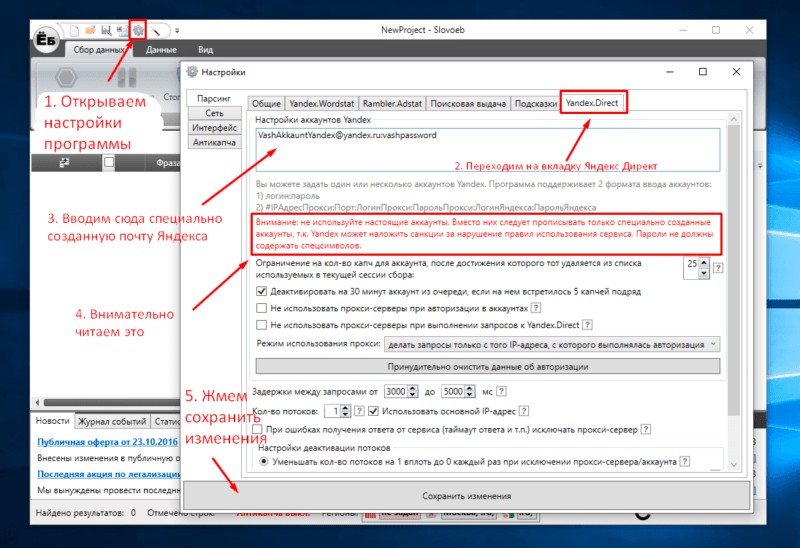
ВНИМАНИЕ! Вам не нужно подключать личную почту к Словоебу, вам нужно создать отдельный аккаунт Яндекса и подключить его.
После того, как мы подключили специально созданную почту Яндекса к Slovoebu, мы переходим в основную панель программы и создаем в ней группы для «грязных ключей» с одноименными названиями. Выглядит это так:
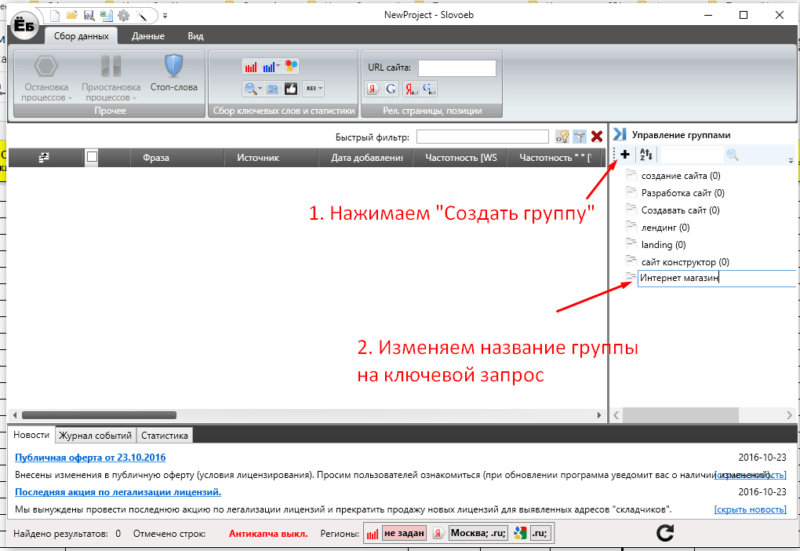
Затем мы выделяем первую группу и начинаем собирать в нее ключевики из левой колонки вордстата. Выглядит это так:
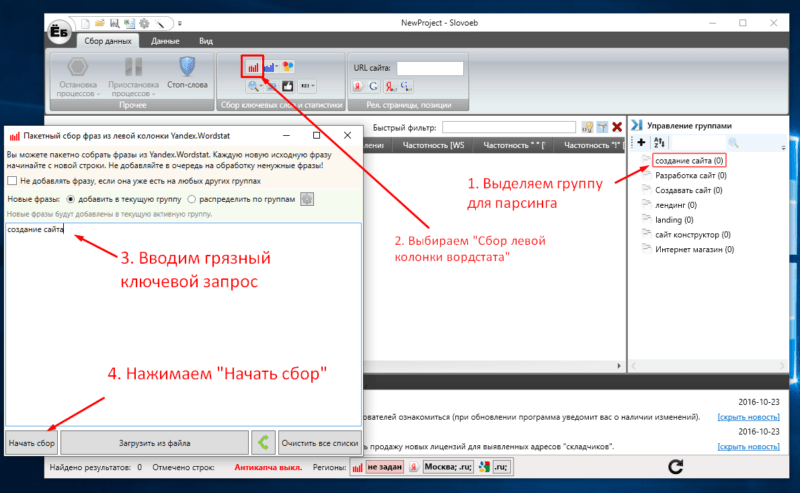
После всех этих махинаций программа начнет собирать ключевые запросы в выбранную группу. По завершению сбора вы увидите большое количество ключевых слов и их «грязную» частотность. Выглядеть это будет примерно так:
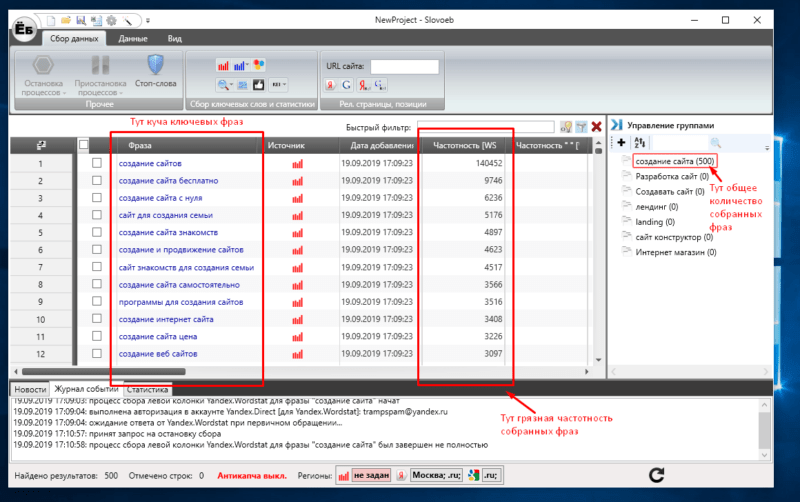
Теперь вам нужно по такому же принципу собрать фразы для всех остальных групп.
После этого можно считать, что первую часть работы мы сделали и собрали поисковые фразы с «грязной частотностью». Теперь нам нужно собрать «чистую» частотность ко всем выбранным фразам.
Шаг 4: Собираем «чистую» частотность ключевиков
Давайте сразу разберемся с «уровнем чистоты ключей» и с тем, на что он влияет. В данный момент у нас есть два вида частотности ключевиков:
Первый вид — «грязная» частотность
«Грязная» частотность — это частота показа какой либо фразы со всеми «хвостами».
Пример: есть фраза «создание сайта», по этой фразе Вордстат покажет цифру в 140 тысяч показов в месяц. Это частотность в 140 тысяч показов — «грязная» частотность, так, как она учитывает частотность любых фраз, которые вводили пользователи вместе с ключом «создание сайта».
Второй вид — «чистая» частотность
«Чистая» частотность — это частота показа какой-либо фразы без «хвостов». Чтобы увидеть чистую частотность, нам нужно поставить запрос в Вордстате в кавычки.
Пример: у нас есть все тот же запрос «создание сайта», но теперь при проверке этой фразы в Вордстате, мы ее поставим в кавычки и увидим «чистую» частотность данной фразы, т.е. сколько раз в месяц пользователи ввели конкретно эту фразу в Яндекс.
Нам очень важно подбирать запросы для статей именно с «чистой» частотностью. Если же мы будем пытаться писать статьи под фразу, без проверки «чистой» частотности, мы рискуем проделать большой объем работы в холостую (ниже будет пример).
Чтобы собрать правильную частотность, мы возвращаемся обратно в Словоеб и выбираем в нем кнопку «сбор частотностей» -> затем нажимаем «Собрать частотность в кавычках».
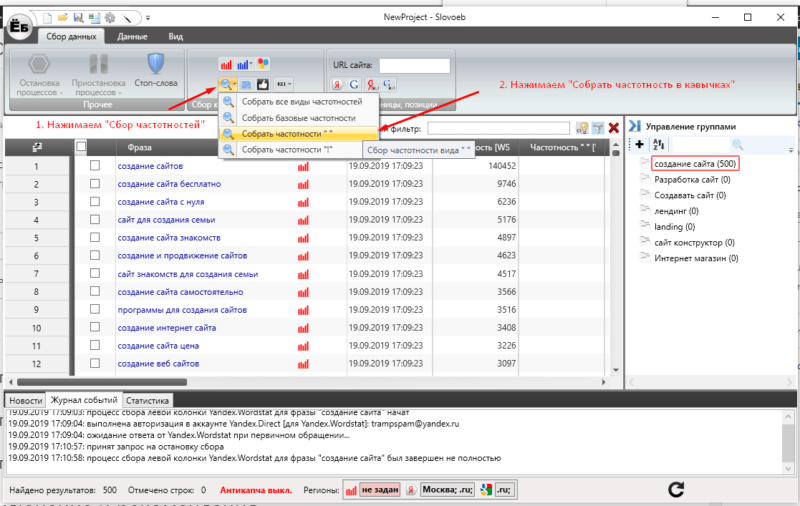
Теперь мы видим реальную картину по частотности у каждого ключевика.
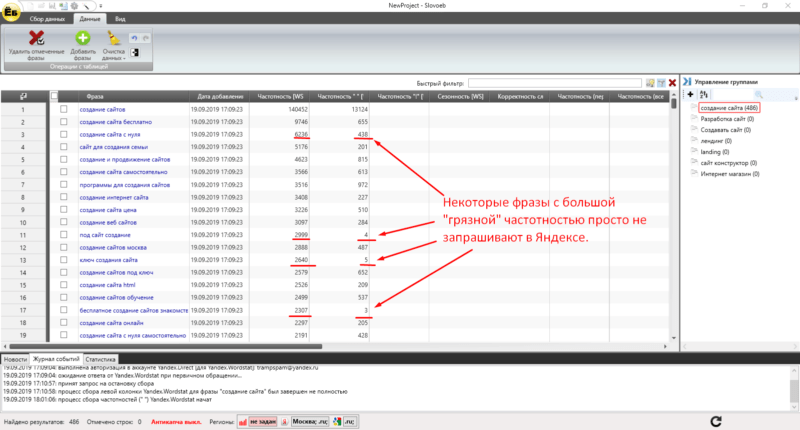
Видите, какая большая разница получается? У некоторых ключей с «грязной» частотностью в 2-3 тысячи показов, на самом деле 0-20 показов в месяц и писать под такие запросы статьи, все равно что лупить из пушки по воробьям.
Шаг 5: Собираем ключи с минимальным уровнем конкуренции
Следующий шаг — это сбор запросов, которые имеют нормальное количество «чистых» показов в месяц и у которых маленький уровень конкуренции.
Что такое запросы с маленьким уровнем конкуренции:
Запросы бывают разного уровня конкуренции (малый, средний, высокий уровень). Уровень конкуренции запроса — это показатель того, сколько сайтов в рунете оптимизировали свои страницы под выбранный запрос. Чем выше конкуренция по запросу, тем больше сайтов под него оптимизировали статью и тем сложнее будет пробиться в ТОП поисковой выдачи по этому запросу.
Соответственно наша задача найти те ключевые фразы, которые имеют нормальное количество «чистых» показов в месяц и у которых маленький уровень конкуренции — эта комбинация позволит нам быстро выйти в ТОП поисковиков по выбранному запросу.
На данный момент я знаю два способа проверить конкуренцию:
1. Геморный, долгий, но бесплатный;
2. Простой, быстрый, но платный.
Геморным способом я не пользуюсь, так, как он требует большое количество времени и внимания, поэтому и рассказывать о нем я тоже не буду. Вместо этого я покажу быстрый и простой способ проверки конкуренции с помощью сервиса Мутаген.
Сразу скажу, этот сервис платный, но стоит он всего 30 копеек за проверку одного ключа. Чтобы вы понимали расскажу про расход средств — в ноябре 2018 года я закинул на баланс Мутагена 350 рублей. На момент написания статьи прошло 10 месяцев, а на балансе еще 20 рублей лежит. Так что расход там минимальный, а вот польза от этого сервиса максимальная, ведь именно благодаря ему вы сможете найти «золотые запросы» с большой частотностью, но маленькой конкуренцией.
Вернемся обратно к поиску малоконкурентных запросов:
Первым делом, чтобы начать проверять конкуренцию нам нужно зарегистрироваться в сервисе Мутаген и сразу после регистрации мы получим 10 бесплатных проверок конкуренции.
После регистрации мы идем обратно к программе Slovoeb и сортируем все запросы по столбцу «Частотность в кавычках». Сейчас наша задача найти подходящие запросы, под которые мы можем написать статью или дать подходящий развернутый ответ (это должны быть те самые запросы по которым вы хотите привлекать пользователей на свой сайт).
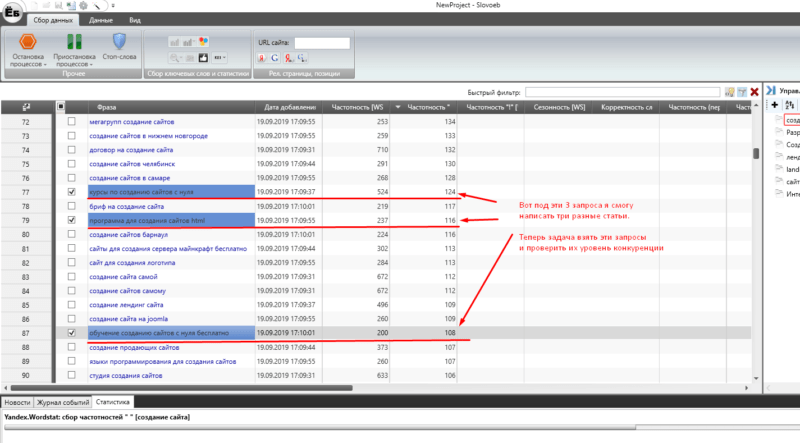
В моем случае, мне подойдут следующие запросы:
— курсы по созданию сайтов с нуля
— программа для создания сайтов html
— обучение созданию сайтов с нуля бесплатно
После того, как мы нашли подходящие запросы, мы копируем их и вставляем в Мутаген.
По тем запросам, что я подобрал у меня получилась следующая картина:
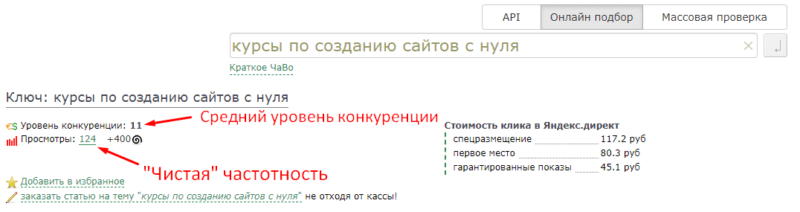

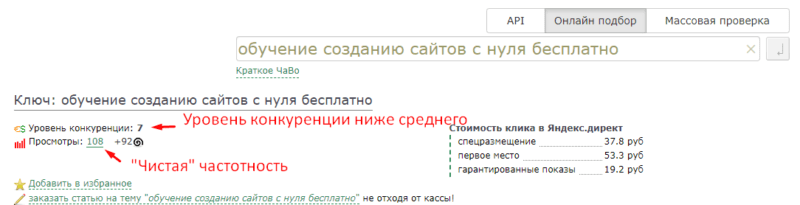
Касательно уровня конкуренции в Мутагене:
В Мутагене есть максимальный уровень конкуренции — 25, все что больше этого уровня, Мутаген не считает.
Наша задача подобрать запросы по следующим критериям:
• Если вашему сайту меньше года — тогда вам нужно искать запросы с конкуренцией 1-8. По запросам с большим уровнем конкуренции вы вряд ли пробьетесь.
• Если вашему сайту больше года — тогда вы можете брать в работу запросы с уровнем конкуренции до 15.
По запросам с уровнем конкуренции больше 15 пробиться будет очень сложно, поэтому не рекомендуется брать их в работу.
Теперь те запросы, которые нам подходят мы берем и добавляем в наше семантическое ядро, вместе со значениями «конкуренция», «частотность», «хвосты». В результате у вас должно получиться следующее:
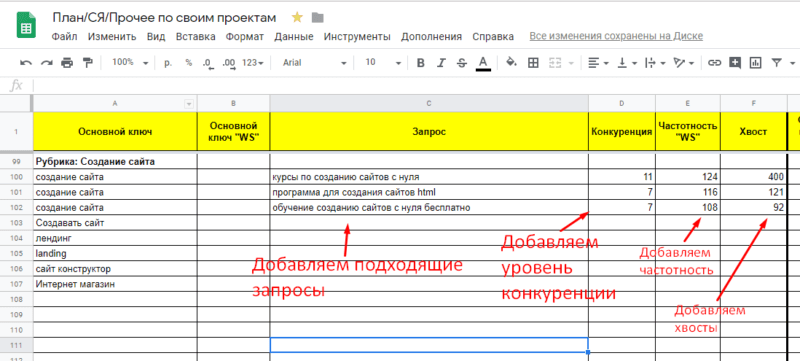
После этого, вам нужно повторить проверку конкуренции для всех остальных подходящих запросов из других направлений. Чтобы не мучатся с каждым ключом в отдельности, можете разом все их выписать и добавить в Мутаген в раздел «Массовая проверка». После этого вам просто нужно будет выбрать из результатов проверки ключевики с подходящим уровнем конкуренции.
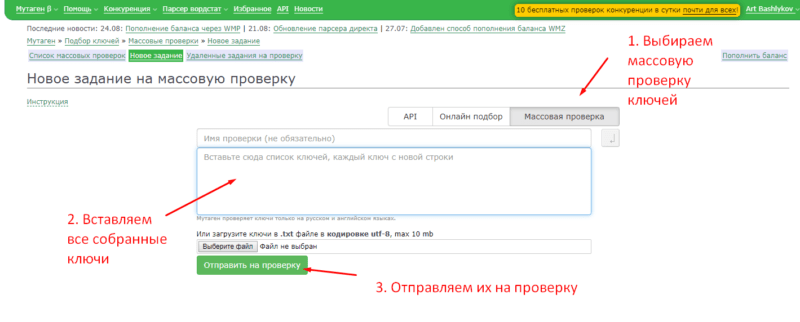
Шаг 6: Подбираем «хвосты» к собранным ключам
Предпоследний шаг — это сбор хвостов к тем ключевикам, которые мы подобрали и которые подошли нам по конкуренции. Сбор хвостов — это сбор всех дополнительных фраз, которые вводят люди вместе с основным ключевым запросом.
Сбор хвостов выглядит следующим образом:
Вы берете какой-нибудь ключ из своего семантического ядра (для примера я возьму ключ «курсы по созданию сайтов с нуля»). Затем открываете Яндекс и вбиваете этот ключ в строку поиска. Все фразы, которые покажет Яндекс поверх вашего основного запроса и будут «хвостами». Выглядит это так:
Все эти «хвосты» люди вводят всего несколько раз в месяц, но именно по ним вы будете получать дополнительный трафик. То есть вам нужно просто взять все эти «хвосты» и добавить в свое семантическое ядро в соответствующий столбец.
В дальнейшем, при написании статьи, вам нужно будет использовать эти хвосты. Можно их использовать вместе с основным ключом, но не обязательно. Вы можете просто добавить их в разные места статьи и по ним к вам также будут приходить пользователи.
Шаг 7: Готовим все к работе
Заключительный этап — это подготовка своего СЯ к работе. Этот этап простой, вы просто сортируете свои запросы по конкуренции или по количеству показов и начинаете составлять из них список дальнейшей работы.
Например на этом этапе я отмечаю, какие способы монетизации я собираюсь использовать в той или иной статей и куда конкретно я собираюсь перегонять трафик.
То есть, грубо говоря вы составляете для себя план действий, которого в дальнейшем нужно будет просто придерживаться. Могу с огромной уверенностью сказать, что работать по плану вам будет намного легче, чем просто каждый раз искать запросы.
На этом составление семантического ядра завершено.
Для тех, кто дочитал до этого места у меня подарок в виде шаблона СЯ для Excel и Google Таблиц (это тот шаблон, что я использую в примерах выше). Скачать его можно тут — шаблон семантического ядра для сайта 2.0.
Заключение и рекомендация
Я думаю что вопрос «Сбор семантического ядра для сайта что это» — мы разобрали целиком и полностью.
Для тех, кто будет собирать СЯ впервые скажу, что это достаточно долгий процесс, который занимает от нескольких дней до нескольких недель. К сожалению быстрее проработать семантику не получиться, поэтому не торопитесь, а спокойно за несколько дней соберите подходящие запросы, проверьте их уровень конкуренции и соберите хвосты.
В результате сбора СЯ у вас должна получиться таблица с содержанием 100-200 ключевых запросов, под которые вы сможете написать статью и сразу начать получать горячий, поисковый трафик.
Что же, на этом все. Если статья оказалась для вас полезной — оцените ее ниже. Если есть что добавить — пишите в комментарии.
 История автора / Сайдбар")